Text-to-video (T2V) generation has gained significant attention recently. However, the costs of training a T2V model from scratch remain persistently high, and there is considerable room for improving the generation performance, especially under limited computation resources. This work explores the continual general pre-training of text-to-video models, enabling the model to ``grow" its abilities based on a pre-trained foundation, analogous to how humans acquire new knowledge based on past experiences. There is a lack of extensive study of the continual pre-training techniques in T2V generation. In this work, we take the initial step toward exploring this task systematically and propose ModelGrow.
Specifically, we break this task into two key aspects: increasing model capacity and improving semantic understanding.
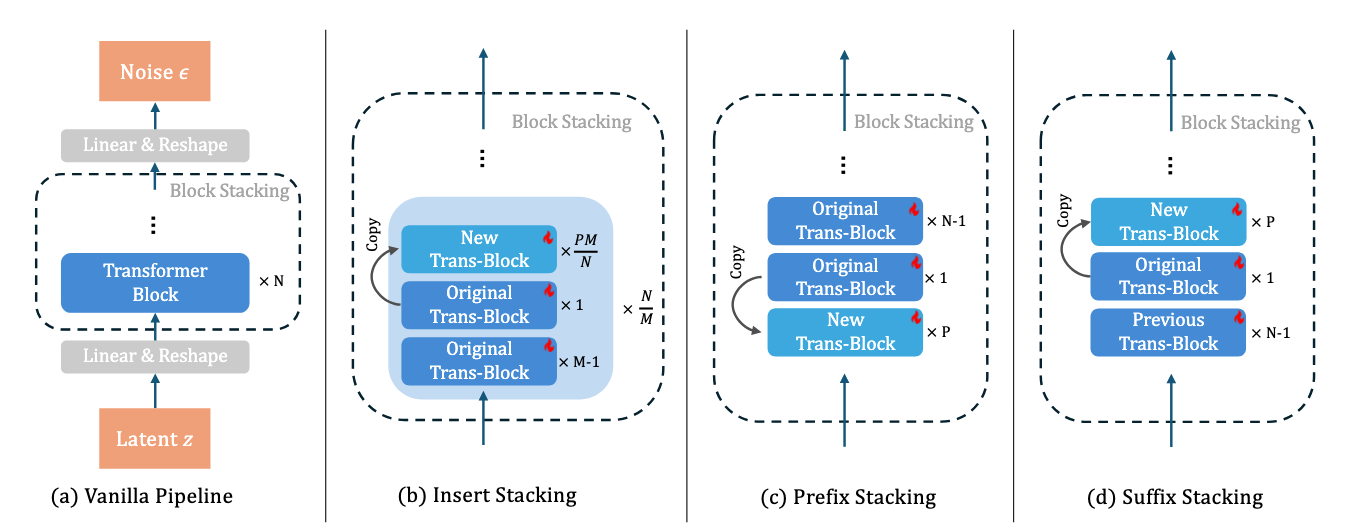
For model capacity, we introduce several novel techniques to expand the model size, enabling it to store new knowledge and improve generation performance.
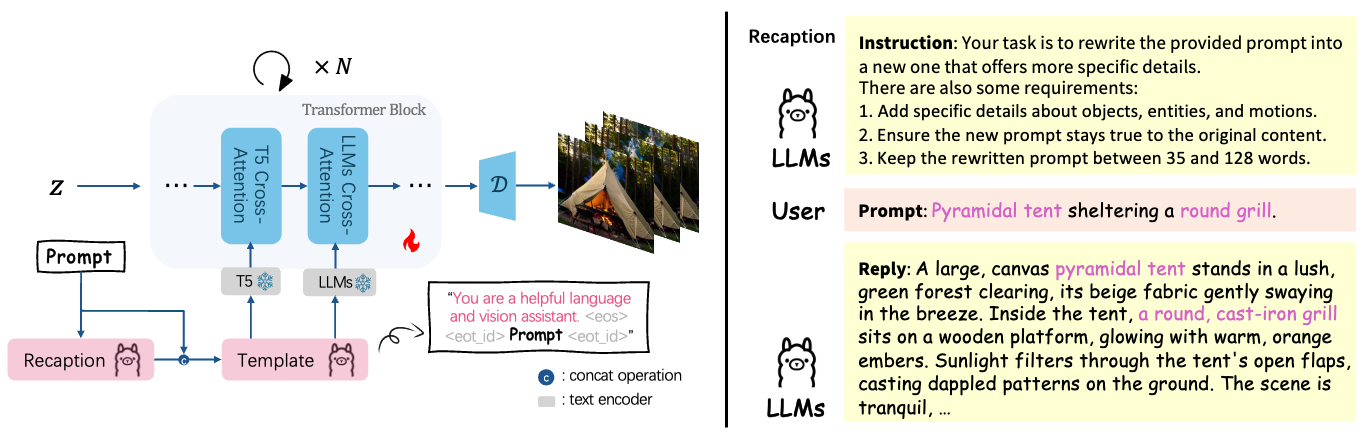
For semantic understanding, we propose a method that leverages large language models as advanced text encoders, integrating them into T2V models to enhance language comprehension and guide generation results according to detailed prompts.
This approach enables the model to achieve better semantic alignment, particularly in response to complex user prompts.
Extensive experiments demonstrate the effectiveness of our method across various metrics. The source code and the model of ModelGrow will be publicly available.